(11/19)
드디어 대망의 파이널 프로젝트가 시작했다. 이번 주제는 총 4가지로 1. Recommendation System 2. NLP 3. Computer Vision 4. 자유 주제(...) 라는 선택지가 주어졌고, 놀랍게도 나의 선택은 자유 주제이다...(스불재)
일단 하고 싶은게 생겼고, 바로 앞에 배운 강의가 추천 시스템이었기 때문에 해보자 싶은 마음이 컸다. (재미추구파)
최종 플젝인만큼 기간도 길고 최대한 배운것들을 모두 적용시켜서 처음부터 끝까지 해보는게 정리하는 관점에서 좋겠다는 생각을 했고, 개인적으로 생활고에 시달리고 있기 때문에...(?) 일하면서 플젝 진행하는 것에 다른 팀원들에게 민폐를 끼치지 않아야겠다 싶어서 개인 프로젝트로 도전한다. (역시 스불재)
미리 말하지만 난 팀 프로젝트를 매우 좋아하는 편이고 내가 생각하지 못했던 것들을 배워가는 과정이 즐겁다고 느끼기 때문에 생활고에 포기할 수 밖에 없는 내 상황이 너무 화가 난다 화가나....!
일단 주제는 '디즈니 플러스 서비스를 기반으로 한 Cold Start Problem 개선과 첫 이용 고객들의 초반 시청 목록 예측' 이다. 솔직히 너무 어려운 문제라는 건 잘 알고 있지만 일단 해보자 싶다. 어떤 추천시스템이든 갖고 있는 고질적인 문제지만 디즈니의 특수성을 적용시켰을 경우에도 과연 문제가 될까?
어쨌든 해보자 해보면 실력은 늘어날테니까 답을 찾지 못해도 다음 스텝은 밟을 수 있겠지 화이탱!!
(11/22)
학원 방문의 날! 대충 가닥은 잡힌 상태이다. 프로젝트 명세서도 러프하게 끝내놓았고 이제 세부화시키기만 하면 된다. 오늘 강사님께 1차 면담 받고 피드백으로 방향을 잡아야겠다. 요즘 코딩테스트랑 면접이랑 아르바이트랑 쉴새없이 이어져서 혀가 갈라졌다....ㅠㅠ 이럴때 필요한건 영양제인데 돈이 없어서 그것도 못사먹는 가난한 1인 청년 가구의 삶이란 후... 그래도 잘하고 있다. 코딩테스트 점수랑 등수도 오르고, 연락오는 회사들도 많으니까 위안 삼으면서 힘내자 힘!!
※ 노션 처음 써봤는데 되게 편하네.... 블로그랑 깃허브랑 병행해야겠당 희희
프로젝트 명세서 : https://www.notion.so/noey26/062bb94b9422429daf1f9f1fda42b29a
(11/23)
처음으로 패파에 가봤다. 거기 계신 분들을 보니 내가 하는 노력은 정말 새 발의 피구나.... 싶었지만, 나름 최선을 다해서 논문도 찾아보고 데이터 구하려고 연락도 돌려놨다. 제발 일말의 정보라도 주셨으면ㅠㅠ 근데 아마 제공받지 못할 가능성이 99%이기 때문에 그 대안을 찾아야 한다. 아직 갖고있는 데이터 정리도 시작 못했는데 다른 분들 말을 들어보니 모델 학습이 7시간 넘게 걸린다고.... 얼릉 빨리 해야겠다. 할게 너무 많아서 조금 힘이 든다.... 할 수 있겠지...? 일단 제일 중요한 플랜B를 세우자 화이팅!!
(11/24)
네이버와 카카오에서 연락을 받았다는 메일을 확인했고, 7일 이내로 답변을 준다고 한다. 하지만 그리 쉬운게 아니란 걸 잘 알고 있기 때문에 대안을 열심히 생각 중이다. 오늘 AI 면접도 보고 스타트업에 보낼 이력서도 쓰고 금요일에 기획안 발표에 사용할 발표자료도 만들고 있으니 굉장히 바쁠것 같다. 하루에 1kg씩 빠지는 중....오히려 좋아(?)
[ Disney+의 기술 ]
데이터로 승부하는 넷플릭스와 차별화를 둔 디즈니는 엄청난 콘텐츠를 제공하는 기술로 사용자를 유입하고 있다.
이는 시장 진출이 넷플릭스보다 훨씬 늦었기 때문에 사용자 데이터가 현저히 부족한 상태이므로 구독료를 넷플릭스의 절반정도로 책정하여 초기 사용자들을 적극적으로 유입하는 방법을 택한 것으로 보인다. -> 초기 사용자가 늘어나는 것은 다양한 데이터를 확보할 수 있다는 뜻이다.
OTT 플랫폼 + Disney Research
다양한 데이터와 인공지능 기술을 여러 방면에서 연구 중이다.
2017년 발표한 추천 관련 기술 중 하나인 프베스(FVAEs, Factorized Variational AutoEncoders)는 관람객들의 표정을 실시간으로 분석하여 영화 평점을 매기는 인공지능이다.
https://www.kaggle.com/shivamb/disney-movies-and-tv-shows
Disney+ Movies and TV Shows
Movies and TV Shows listings on Disney+
www.kaggle.com
https://studios.disneyresearch.com/artificial-intelligence/
Artificial Intelligence | Disney Research Studios
We are working to endow computers and robots with many of the qualities long associated with living, thinking beings—from perception and action to reasoning, problem solving, and even creativity! Here we are going beyond simply building the next generati
studios.disneyresearch.com
※ Data set은 Disney Research와 Disney+ 웹 크롤링으로 수집 + kaggle 대회에서 제공한 데이터
[ 추천(필터링) 시스템 ]
1. 내용 기반 필터링 (Content-based Filtering)
콘텐츠 자체의 특성을 분석하고 이를 기반으로 추천을 진행하는 필터링 방식이다.
다른 사용자의 데이터를 필요로 하지 않는다는 장점이 있지만, 선호하는 특성을 가진 항목만을 계속해서 반복 추천할 여지가 있다는 점에서 단점을 지니고 있기도 하다.
2. 협업 필터링 (Collaborative Filtering)
'집단 지성'처럼 사용자 간의 특징을 통해 추천을 하는 시스템이다.
항목의 내용에 대해서 상세하게 파악해야 할 필요가 없다는 장점이 있으나, 소수의 인기 있는 콘텐츠가 중복되어 추천되면서 소수의 콘텐츠에만 관심이 쏠리게 된다는 단점이 존재한다.
3. 모델 기반 협업 필터링 (Model-based Collaborative Filtering)
'협업 필터링(Collaborative Filtering)'의 종류는 크게 'Memory-based'와 'Model-based'로 나뉜다.
메모리 기반 협업 필터링 (Memory-based CF)은 전통적인 방법으로 이미 있는 데이터를 바탕으로 필터링을 하는 것을 의미한다.
모델 기반 협업 필터링 (Model-based CF)은 기계 학습을 이용하여 사용자와 아이템의 숨겨진 특성 값들을 분석하는 방법이다. 이 방식은 기존 항목 간의 유사성을 단순하게 비교하는 것이 아니라, 자료 안에 내재화 된 패턴을 이용하는 방법이라고 할 수 있다. 이를 위한 첫 번째 방법은 바로 관련되는 자료의 크기를 동적으로 변화시키는 방법이다.
이렇게 추천을 위한 자료의 크기를 변화시키는 방법도 있지만 현재는 잠재(latent) 모델을 기반으로 두고 있는 알고리즘이 가장 주목을 받고 있다고 한다. 이는 특정 항목 사용자가 좋아하는 이유를 알고리즘적으로 알아내는 방법이라고 할 수 있다. 이 필터링을 통해 사용자와 항목의 특성들은 더 세분화되며, 이를 바탕으로 더욱 정밀하고 정확한 추천이 진행된다.
★ Hybrid Recommendation Systems
1. Weighted
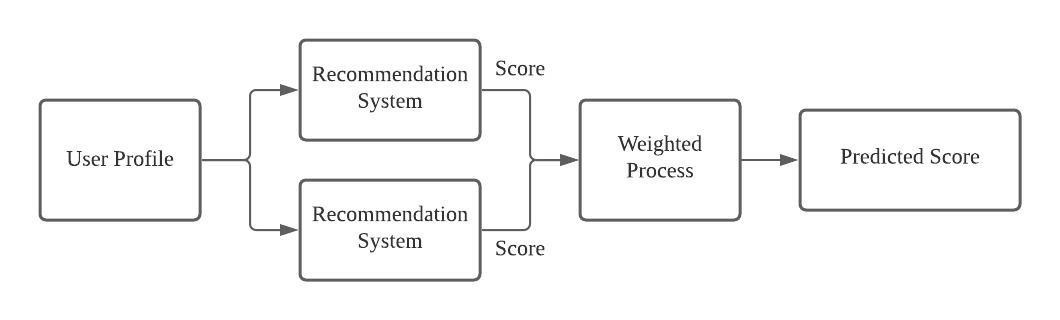
Weighted Hybrid Recommendation System (WHRS)은 데이터셋을 잘 해석할 수 있는 몇 가지 모델들을 정의할 수 있다. WHRS는 여러 가지의 모델들의 Outputs를 가져와 train set과 test set에 걸쳐 가중치가 변하지 않는 정적 가중치 결과로 결합한다.
예를 들어, content-based model과 item-item collaborative filtering model을 결합할 수 있고, final prediction으로 50%의 가중치를 갖는다.
WHRS의 장점은 몇 가지 모델을 통합하여 추천 프로세스의 데이터셋을 선형으로 지원한다는 것이다.
2. Switching

Switching Hybrid Recommendation System (SHRS)은 상황에 따라서 단일 추천 시스템을 선택한다. 이 모델은 Item-level sensitive dataset에 맞춰 제작되었으므로 사용자 프로필이나 기타 기능을 기반으로 추천자 선택 기준을 설정해야 한다.
SHRS는 사용할 적절한 모델을 선택하는 추천 모델에 추가적인 layer를 도입한다. recommender system은 constituent recommendation model의 강점과 약점에 민감하다.
3. Mixed
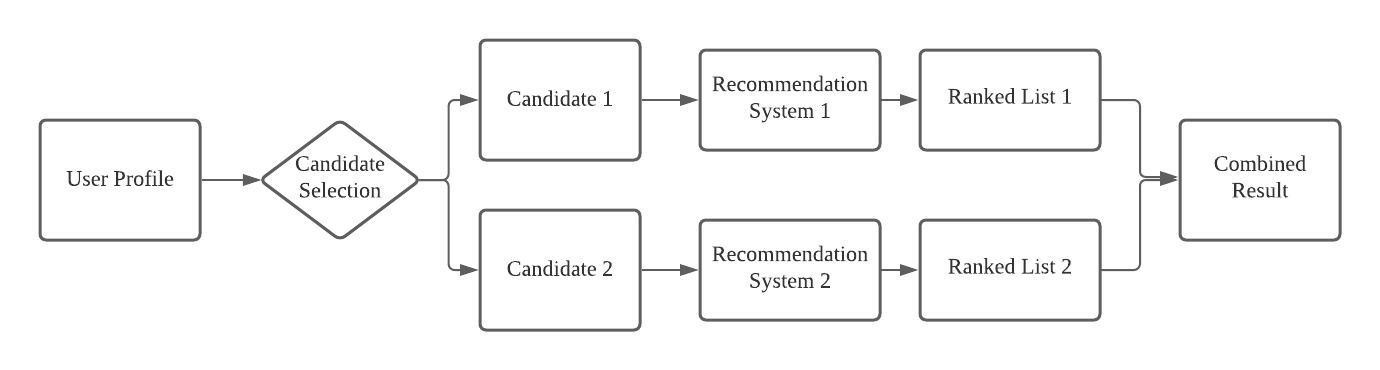
Mixed Hybrid Recommendation System (MHRS)은 처음에 사용자 프로필과 기능을 사용하여 다양한 후보 데이터셋을 생성한다. 추천 시스템은 그에 따라 추천 모델에 서로 다른 후보 세트를 입력하고, 예측을 결합하여 결과 추천을 생성합니다.
MHRS는 많은 수의 권장 사항을 동시에 제공할 수 있으며, 성능을 향상시키기 위해 부분 데이터셋을 적절한 모델에 맞출 수 있다.
4. Feature Combination

Figure Combination Recommendation System (FCRS)은 오리지널 사용자 프로필 데이터셋에 대한 기능 엔지니어링으로서 작동하는 Virtual Contributing 추천 모델을 시스템에 추가한다.
예를 들어, collaborative recommendation 모델의 특징을 content-based recommendation 모델에 넣을 수 있다. hybrid model은 하나의 모델에만 의존하여 하위 시스템의 collaborative data를 고려할 수 있다.
5. Feature Augmentation

사용자/아이템 프로필의 등급이나 분류를 생성하기 위해 도움을 주는 contributing recommendation model이 사용되며, 이는 final predicted result를 생성하기 위한 주요 추천 시스템에서 추가로 사용된다.
Feature Augmentation Hybrid Recommendation System (FAHRS)은 main recommendation model의 변화없이 core system의 성능을 향상시킬 수 있다. 예를 들어, 연결 규칙을 사용하여 사용자 프로필 데이터셋을 향상시킬 수 있다. augmented 데이터셋을 통해 content-based recommendation model의 성능이 향상될 것이다.
6. Cascade

Cascade Hybrid Recommendation System (CHRS)은 엄격한 계층 구조 추천 시스템(strict hierarchical structure recommendation system)을 정의하여 main recommendation system이 primary result를 생성하도록 하고, 2차 모델을 사용하여 점수 차이와 같은 1차 결과의 사소한 문제를 해결한다.
실제로 대부분의 데이터셋은 희소하며, 2차 추천 모델은 동점 문제 또는 누락 데이터 문제에 대해 효과적일 수 있다.
7. Meta-Level
Meta-Level Hybrid Recommendation System (MLHRS)은 feature augmentation hybrid와 유사하여 contributing model은 main recommendation model에 augmented 데이터셋을 제공한다. feature augmentation hybrid와는 달리, MLHRS는 main recommendation model에 대한 입력으로 contributing model에서 학습된 모델로 original 데이터셋을 대체한다.
참고)
https://medium.com/analytics-vidhya/7-types-of-hybrid-recommendation-system-3e4f78266ad8
7 Types of Hybrid Recommendation System
Combining multiple recommendation system techniques to effectively predict the users’ habit
medium.com
'빅데이터' 카테고리의 다른 글
| [ADP] 더 나아가 보자 앞으로 앞으로. (0) | 2022.10.04 |
|---|---|
| [ADsP] 새로운 공부를 시작해볼까요-? (완료) (0) | 2022.07.30 |
| [WandB] WandB 알아보기 정리 (0) | 2021.11.11 |
| [Computer Vision] 01. OpenCV 정리 (0) | 2021.11.04 |
| [EDA] PIL(Python Imaging Library) pillow 정리 (0) | 2021.11.03 |


